
Modern Harnessing Meets In-Memory Fuzzing - PART 1
Fuzzing or Fuzz Testing is an automated software testing technique that involves providing invalid, unexpected, or random data as inputs to a computer program then observe how the program processes it.
In one of our recent projects, we were interested in fuzzing closed source applications (mostly black-box). While most standard fuzz testing mutates the program inputs which makes targeting these programs normally take lot of reverse engineering to rebuild the target features that process that input. We wanted to enhance our fuzzing process and we came across an interesting fuzzing technique where you don't need to know so much about the underlying initialization and termination of the program prior to target functions which is a tedious job in some binaries and takes a lot of time to reverse and understand. Also, that technique has the benefit of being able to start a fuzz cycle at any subroutine within the program.
So we decided to enhance our fuzzing process with another fuzzing technique, Introducing: In-Memory Fuzzing.
A nice explanation of how in-memory fuzzing works is by Emanuele Acri : "If we consider an application as “chain of function” that receives an input, parses and processes it then produces an output, we can describe in-memory fuzzing as a process that “tests only a few specific rings” of the chain (those dealing with parsing and processing)".
And based on many fuzzing articles there are two types of in-memory fuzzing:
- Mutation loop insertion where it changes the program code by creating a loop that directs execution to a function used previously in the program.
- Snapshot Restoration Mutation where the context and the arguments are saved at the beginning of the target routine then context is restored at the end of the routine to execute a new test case.
We used the second type because we wanted to execute the target function at the same program context with each fuzzing cycle.
In one of our fuzzing projects, we targeted Solid framework, we were able to harness it fully through their SDK, but we wanted to go the extra mile and fuzz Solid using Adobe Acrobat’s integration code. Acrobat uses adobe with a custom OCR and configuration than the normal SDK provide, which caught our interest to perform fuzzing through Acrobat DC directly
This blog post will introduce techniques and tools that aid in finding a fuzzing vector for a feature inside a huge application. Finding a fuzzing vector vary between applications as there is no simple way of finding fuzzing vectors. No worries, though. We got you covered. In this blogpost we’ll introduce various tools that’ll make binary analysis more enjoyable.
Roll up your sleeves and we promise you by the end of this blog post you will understand how to Harness Solid Framework as Acrobat DC uses it :)
Finding a Fuzzing Vector
Relevant code that we need to analyze
The first step is identifying the function that handles our application input. To find it, we need to analyze the arguments passed to each function and locate the controllable argument. We need to locate an argument that upon fuzzing it, it will not corrupt other structures inside the application. We implemented our fuzz logic around the file path that we can control, the file path is in the disk provided to a function that parse the content of the file.
Adobe Acrobat DC divides its code base into DLLs, which are shared library that Adobe Acrobat DC loads at run-time to call its exported functions. There are many DLLs inside Adobe Acrobat and finding a specific DLL could be troublesome. But from the previous post, we know that Solid provides its DLLs as part of their SDK deliverable. Luckily, Acrobat have a separate folder that contains Solid Framework SDK files.
Solid comprises quite a number of DLLs. This is no surprise since it parses pdf files that are complex in its format structure and supports more than seven output formats (docx, pptx, ...). We’ll needed to isolate the relevant DLL that handles the conversion process so we can concentrate on the analysis of a specific DLL to find a fuzzing vector that we can abuse to perform in-memory fuzzing.
By analyzing Acrobat DC with WinDBG, we can speed up the process of analyzing Solid DLLs by knowing how Acrobat DC loads them. Converting a PDF To DOCX will make Acrobat DC load the necessary DLLs from Solid.

Using WinDBG we can monitor certain events. The one event that we are interested in is ModLoad. This event gets logged in the command output window when the process being debugged loads a DLL. It’s worth noting that we can keep a copy of WinDBG’s debugger command window in a file by using the .logopen command and provide a path to the log file as an argument. Now convert a PDF to a word document to exercise the relevant DLL and finally closing the log file using .logclose after we finish exporting to flush the buffer into the log file.
Before we view the log file we need to filter it using string `ModLoad` to find the DLLs that got loaded inside Acrobat process, sorted by their loading order.
SaveAsRTF.api, SCPdfBridge.dll and ConverterCoreLight.dll appear to be first DLLs to be loaded and from their names we conclude that the conversion process starts with these DLLs.
Through quick static analysis we found out that their role in the conversion is as follows:
SaveAsRTF.api is an adobe plugin, Acrobat DC plugins are DLLs that extend the functionality of Adobe Acrobat. Adobe Acrobat Plugins follow a clear interface that was developed by adobe that allows plugin developers to register callbacks and menu Items for adobe acrobat. Harnessing it means understanding Adobe’s complex structures and plug-in system.
Adobe uses SCPdfBridge.dll to interact with ConverterCoreLight.dll, Adobe needed to develop an adapter to prepare the arguments in a way that ConverterCoreLight.dll accepts. Harnessing `SCPdfBridge.dll` is possible but we were interested in ConverterCoreLight because it handled the conversion directly.
ConverterCoreLight.dll is the DLL responsible of converting PDF files into other formats. It does so by exporting a number of functions to SCPdfBridge.dll. Functions exported by ConverterCoreLight.dll mostly follow a C style function exporting like: PdfConverterCreate, PdfConverterSetOptionInt, PdfConverterSetConfiguration and finally the function we need to target is PdfConverterConvertEx

Recording TTD trace
Debugging a process is a practice used to understand the functionality of complex programs. Setting breakpoints and inspecting arguments of function calls is needed to find a fuzzing vector. Yet it's time consuming and prone to human errors..
Modern debuggers like WinDBG Preview provide the ability to record execution and memory state at the instruction level. WinDBG Preview is shipped with an engine called TTD (Time Travel Debugging). TTD is an engine that allows recording the execution of a running process, then replay it later using both forward and backward (rewind) execution.
Recording a TTD Trace can be done using WinDBG Preview by attaching and enabling TTD mode. It can also be done through a command line tool:
Recording a trace consumes a high amount of disk space. To overcome this problem, instead of recording the whole process from the beginning; we open a pdf document under Acrobat DC and then before triggering the conversion process, we attach the TTD engine using the command line to capture the execution. After the conversion is done we can kill the Acrobat DC process and load the output trace into WinDBG Preview to start debugging and querying the execution that happened during the conversion process thus we isolated the trace to only containing the relevant code we want to debug.
Since we have a TTD trace that recorded the integration of Adobe and Solid Framework, then replaying it in WinDBG allows us to execute forward or backward to understand the conversion process.
Instead of placing a breakpoint at every exported function from ConverterCoreLight.dll we can utilize TTD query engine to retrieve information about every call directed to ConverterCoreLight.dll by using the dx command with the appropriate Link object.
- Querying Calls information to ConverterCoreLight module.
TTD stores an object that describes every call. As you can see from the above output, there are a couple of notable information we can use to understand the execution.
ThreadId: Thread Identifier
All function calls were executed by the same thread.
TimeStart, TimeEnd: Function start and end positions inside the trace file.
FunctionAddress: is the address of the function. Since we don't have symbols, the Function member in the object point to UnknownOrMissingSymbols.
ReturnValue: is the return value of the function upon return which usually ends up in the EAX register.
Before analyzing every function call, we can eliminate redundant function calls made to the same FunctionAddress by utilizing the LINQ Query engine.
- Grouping function calls by FunctionAddress
NOTE: the output above was enriched manually by adding the symbol of every function address by utilizing the disassembly command `u` on each address.
Now we have a list of functions that handles the conversion process that we want to fuzz. Next, we need to inspect the arguments supplied to every function so that we findan argument we can target in fuzzing. Our goal is to find an argument that we could control and modify without affecting the conversion process or corrupting it.
In this context, the user input is the pdf file to be converted. Some of the things that we need to figure out is how Adobe passes the PDF content to Sold for conversion. We also need to inspect the arguments passed and figure out which ones are mutation-candidates.
Function calls are sorted, we won't dig deep in every call and but will briefly mention the important calls to keep it minimal.
Function calls that are skipped:
ConverterCoreLight::ConverterCoreLight, PdfConverterSetTempRootName, ConverterCoreServerSessionUnlock, GetConverterCoreWrapper, PdfConverterAttachProgressCallback, PdfConverterSetOptionData, PdfConverterSetConfiguration, PdfConverterGetOptionInt
Analyzing Function Calls to ConverterCoreLight
ConverterCoreLight!PdfConverterCreate
PdfConverterCreate takes one argument and returns an integer. After reversing sub_1000BAB0 we found out that a1 is a pointer to the SolidConverterPDF object. This object holds conversion configuration and is used as a context for future calls.
ConverterCoreLight!PdfConverterSetOptionInt
PdfConverterSetOptionInt is used to configure the process of conversion. By editing the settings of the conversion object, Solid allows the customization of the conversion process which affects the output. An example, is whether to use OCR to recognize text in a picture or not.
PdfConverterSetOptionInt is used to configure the process of conversion. By editing the settings of the conversion object, Solid allows the customization of the conversion process which affects the output. An example, is whether to use OCR to recognize text in a picture or not.
From the arguments supplied we noticed that the first argument is always a `SolidConverterPDF` object created from `PdfConverterCreate` and passed as context to hold the configuration needed to perform the conversion. Since we want to mimic the normal conversion options we will not be changing the default settings of the conversion.
We traced the function calls to `PdfConverterSetOptionInt` to show the default settings of the conversion.
Note: The above are default settings of Acrobat DC
ConverterCoreLight!PdfConverterConvertEx
PdfConverterConvertEx accepts a source and destination file paths. From the debug log above we notice that `a3` points to the source PDF file. Bingo, that can be our Fuzzing Vector that we can abuse to perform an in-memory fuzzing.
Testing with Frida
Now that we found a potential attack vector to abuse which is in PdfConverterConvertEx. The function accepts six arguments. The third argument is the one of interest. It represents the source pdf file path to be converted.
Next should be easy right ? just intercept PdfConverterConvertEx and modify the third argument to point to another file :)
Being Haboob researchers, we always like to make things fancier. We went ahead and used a DBI (Dynamic Binary Instrumentation) engine to demo a POC. Our DBI tool of choice is always Frida. Frida is a great DBI toolkit that allows us to inject JavaScript code or your own library into native apps for different platforms such as windows, iOS etc...
The following Frida script intercepts PDFConverterConvertEX:
So running the script above will intercept PDFConverterConvertEX and when adobe reader calls PDFConverterConvertEX we changed the source file path (currently opened Document) to our path which is “C:\\HaboobSa\Modified.pdf”. What we are expecting here is the exported document should contain whatever inside Modified.pdf and not the current opened pdf.
Sadly that didn't work :(, Solid converted the currently opened document and not the document we modified through Frida. So what now!
Well, During our analysis of ConverterCoreLight.dll we noticed that there is another exported function with the name PDFConverterConvert that had a similar interface but only differs in the number of the arguments (5 instead of 6). We added a breakpoint on that function, but the problem is that function never gets called when exporting pdf to word document.
So we went back to inspect it even further in IDA:



As we can observe from the image above both PDFConverterConvertEx and PDFConverterConvert are wrappers to a function that does the actual conversion but differ slightly and call the same function. We named that function pdf_core_convert.
Same arguments passed to Ex version are passed to PDFConverterConvert except for the sixth argument in PDFConverterConvertEx version is passed as the fifth argument in PDFConverterConvert. Because The fifth argument in PDFConverterConvertEx version is constructed inside PDFConverterConvert.
In order to hijack execution to PDFConverterConvert, we used Frida's `Interceptor.replace()` to correct the argument number to be 5 instead of 6 and their order.
The diagram below explains how we achieved that:
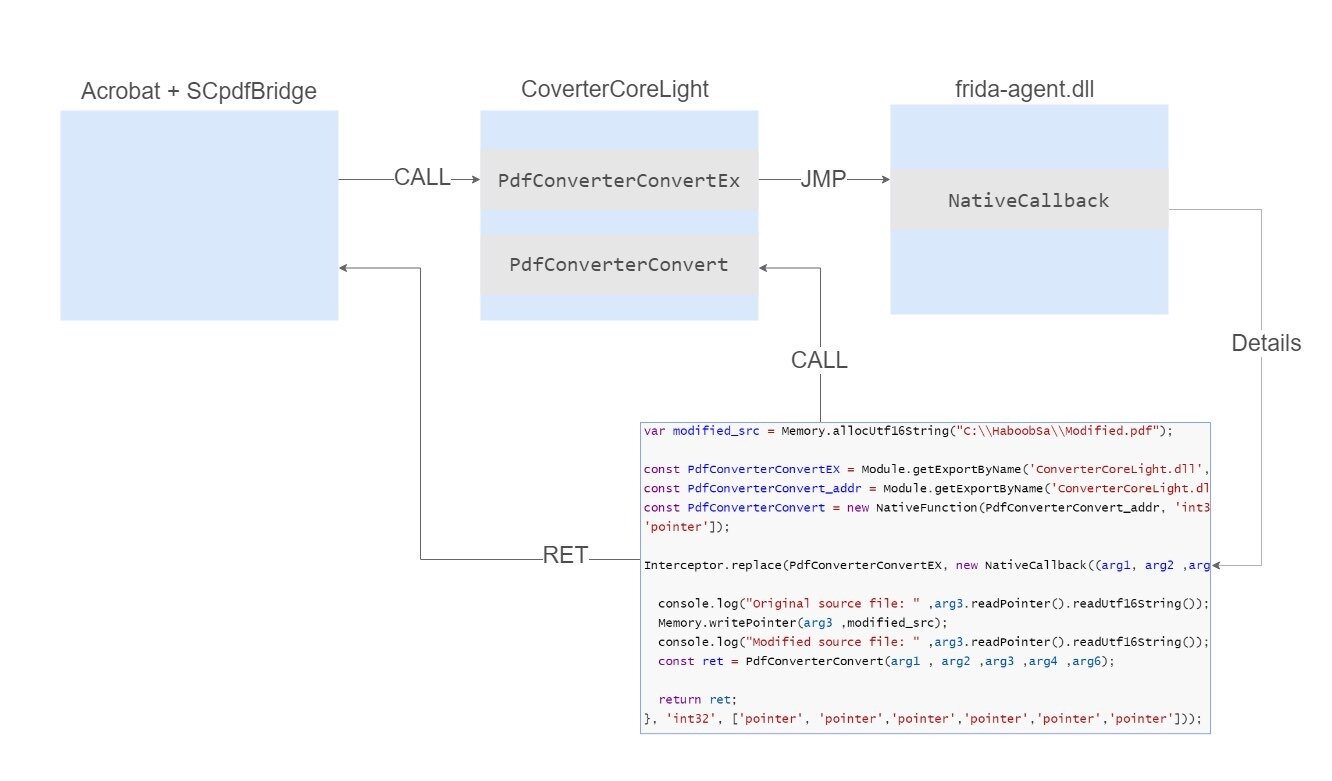
It worked :)
So, probably whatever object in EX_arg5 was created based on the source file which is the currently opened document this why it didn't work when we modified the source file in EX version. While PDFConverterConvert internally takes care of the creation of that object based on the source file .
Now we can create a fuzzer that hijacks execution to PDFConverterConvert with the mutated file path as source file at each restoration point during our in-memory fuzzing cycles.
In the next part of the blogpost, we will implement a fuzzer based on the popular framework WINAFL. The results we achieved from In-memory fuzzing were staggering, this is how we owned Adobe’s security bulletins two times in a row, back-to-back.
Until then!
Resources:
https://en.wikipedia.org/wiki/Fuzzing
https://crossbowerbt.github.io/in_memory_fuzzing.html
https://diglib.tugraz.at/download.php?id=576a78fa4aae7&location=browse
https://docs.microsoft.com/en-us/windows/win32/api/minwinbase/ns-minwinbase-debug_event